데이터 분석을 하거나, 머신러닝, 딥러닝 종류의 분석을 하려면, 통계학은 기본적으로 알고 가야 한다. 이것의 의미를 모르면, 어떠한 강의를 듣더라도 이해를 잘 못할 뿐 아니라, 어떠한 과제가 주어 졌을때, 기본적인 툴만 사용해서 해석 하는 Tooler 가 될수 있다.
Tooler 가 되면, 모든 분석에 있어서 Overfitting과 Underfitting에 대한 해석을 못해 분석 후 시스템에 적용시, 모델 결과 값은 좋은데, 실무에 적용하기 어려운 케이스가 매우 많다.
모집단(母集團, pupulation)과 표본(標本, sample)
어떠한 사물의 특징이나 현상을 알 필요가 있는 경우가 많다. 이러한 경우 일반적으로 관찰이나 측정을 해야 한다. 이러한 관찰이나 측정의 대상이 되는 사물이나 현상의 전체를 모집단(母集團, pupulation)이라고 한다.
그러나 특별한 경우를 제외하고 모집단의 양이 너무 커서 모집단 전체를 관찰하거나 측정 하는 것은 거의 불가능 하다.
실제로 관찰하기 위해 측정된 일부를 표본(標本, sample) 이라고 한다.
표본을 가지고 올때, 우리는 샘플링 하여, 표본을 가지고 온다. 보통 샘플링 할때는 우리는 Random 하게 샘플링하여 데이터를 추출 하는 경우가 많다.
흩어짐(dispesion)과 분포(分布, distribution)
어떠한 대상을 측정 하였을 경우, 얻어지는 측정값은 언제나 일정한 하나의 값이 아니고, 각각 다른 값이 되는 것이 일반적이다. 이렇게 측정값의 크기가 고르지 않은 것을 흩어집(dispersion)이라 하고, 이 흩어짐의 상태를 분포(分布, distribution)라고 한다.
표본평균(標本平均, sample mean)과 표본분산(標本分産, sample variance)
측정치의 크기는 일반적으로 다르므로 어떠한 분포를 사용하게 된다. 측정치의 분포상태를 정량적으로 나타내면 비교 등에 매우 편리하다.
분포상태를 나타내는 특성 중, 가장 중요한것이 1) 분포의 중심과 2) 흩어짐 정도 일것이다.
분포의 중심을 나타내는 양으로서 평균값이 사용되며, 표본에 대해서는 다음과 같이 산술(算術)평균으로 얻어 진다.
아래와 같은 기호를 사용하며, "바" 라고 부른다.
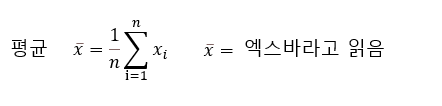
흩어짐의 정도를 나타내는 것은 평균값에서 값이 어느정도 떨어져 있는 가에 대한 것은로 데이터 양이 흩어짐의 정도를 나타낸 것을 분산(分産, variance) 라 한다.

예제 ) 평균 및 분산
어느 야구선수의 15년간 평균 홈련 데이터를 나타낸 것이다. 홈련의 평균과 분산을 R로 구현 하여라.
> # 홈련값의 변수를 x라고 한다.
> x = c(24, 22, 26, 24, 18, 25, 24, 23, 24, 20, 26, 25, 21, 27, 29)
> plot(x)
> # 평균값을 구한다.
> mean(x)
[1] 23.86667
> #분산을 구한다.
> var(x)
[1] 7.838095
공식은 조금 복잡 하지만, 평균은 mean() 함수를 사용하고 분산은 var() 함수를 사용한다.
치우침(bias)
어떠한 측정 대상이 값이 하나의 값이라 해도, 많은 회수를 측정을 하면 측정 값 언제나 하나의 값으로 측정되지 않고, 여러 값으로 측정 되는 것이 일반적이다. 이 때, 측정치 분포의 중심, 즉 평균값과 참값과의 차이를 치우침(bias)라 한다.
참값
원래 참값이란 모르는 값이나 측정 분야에서는 참값을, 대상이 되고 있는 양이 모범적인 방법(exemplar method), 즉 얻어진 데이터가 궁극적으로 사용될 목적에 대해 충분히 정확하다고 전문가들이 동의한 방법에 의해 측정되었을 때 얻어지라고 생각되는 값으로 보고 있다.
'4차 산업에 필요한 분석 R > 통계와 확률 및 확률분포' 카테고리의 다른 글
| 확률변수 및 확률 밀도 함수 (7) | 2022.01.02 |
|---|