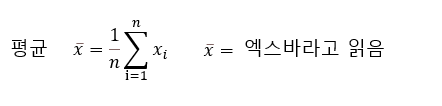확률변수(確率變數, random variable)
어떠한 값이 되는가 하는 것이 확률 법칙에 의해 결정되는 변수를 확률변수 (random variable) 라 한다.
- 값이 이산적(離酸的, dirscrete) 일 때, 이산형(離酸形) 확률 변수
- 값이 연속적(連續的, continuous) 일 때 , 연속형(連續形) 확률변수라 한다.
확률변수라는 총체적인 의미를 나타낼 때에는 X와 같이 대문자로 나타내고, 확률변수의 표본값(데이터)으로서 실제값을 나타낼 때에 x와 같이 소문자로 나타내는 것이 일반 적인 표현 방법이다.
확률밀도함수(確率密度函數ㅡ probability density function, p.d.f)
확률변수 X 가 a ≤ X ≤ b의 값을 가지는 확률 P(a ≤ X ≤ b)가
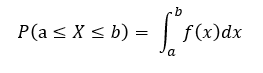
와 같이 나타낼 수 있을 때, f(x)를 확률밀도함수(確率密度函數ㅡ probability density function)라 한다.
f(x)에는 다음과 같은 성질이 있다.

반대로 이 두 조건을 만족하는 함수는 모두 확률밀도함수가 될 수 있다.
위 그래프 "1.확률밀도 함수"의 확률을 도식적으로 나타내면 아래 (a)의 빗금친 부분의 면적에 해당하며, 특히 어떠한 특정한 값 x를 가질 확률은, 식 "2.확률밀도 함수의 성질" 과 같이 a와 b를 한없이 x 값에 접근 시킨 경우의 값으로 얻어지며, (b)와 같이 x에서 dx 를 생각하여 x와 x+dx 사이의 확률 f(x)dx 로 정의 할수 있다.

확률 밀도 함수 이것만 보면, 무엇을 설명 하고 싶은 건지 알수 없다.
아래의 예제를 보면 확률밀도 함수의 구간을 구하는 코드가 있다. 확률밀도 함수는 0~1까지의 숫자로 나타내며, 그 합이 1이여야 한다. 결국 확률 100% 넘지 못한다는 것이다. 구간으로 따지면 0 ≤ x ≤ 1 이다. 아래는 평균이 0이고 표준편차가 1인 정규분포의 밀도함수를 그린 것이고, -2 ≤ x ≤ -1 까지의 구간을 빗금 친 것이다.
# 평균이 0이고 표준편차가 1인 정규분포의 밀도함수를 만든
# 이후 -2 부터 -1까지의 확률 밀도 함수의 그래프 구간을 그리면
par(mfrow = c(1, 1))
x <- seq(-3, 3, length = 100)
y <- dnorm(x)
plot(x, y, type = "l")
xlim <- x[-2 <= x & -1 >= x]
ylim <- y[-2 <= x & -1 >= x]
xlim <- c(xlim[1], xlim, tail(xlim, 1))
ylim <- c(0, ylim, 0)
polygon(xlim, ylim, density = 20)
'4차 산업에 필요한 분석 R > 통계와 확률 및 확률분포' 카테고리의 다른 글
| 통계와 확률에 대한 기본지식 (4) | 2022.01.02 |
|---|